
Annonce des Subventions pour les Ensembles de Données sur la Santé
19 May 2022Aujourd’hui, nous sommes fiers de vous annoncer la première série de subventions du Lacuna Fund pour la création d’ensembles de données dans le domaine de la santé. Les équipes qui ont été sélectionnées pour bénéficier d’un financement débrident le potentiel de l’apprentissage machine dans le monde entier, des provinces rurales du Népal aux banlieues de Chicago, aux États-Unis. Ce financement et le travail des équipes du projet permettront de créer, d’augmenter et de consolider des ensembles de données ouvertes qui sont représentatifs des populations touchées et qui sont donc moins biaisés et plus susceptibles de mener à des résultats équitables en matière de santé dans le monde entier.
Nous tenons à exprimer notre immense gratitude à notre Groupe consultatif technique sur la santé 2021 et aux examinateurs partenaires, qui ont joué un rôle déterminant dans la sélection de projets à même d’avoir un impact sur les communautés, les différents secteurs et le monde entier :
- Dr Alistair Johnson, Hospital for Sick Children
- Chinasa T. Okolo, Cornell University
- Dr Clement Adebamowo, University of Maryland School of Medicine
- Dr Curtis P. Langlotz, Stanford University
- Dr Ivor Braden Horn, Google
- Dr Mahlet (Milly) Zimeta, Open Data Institute
- Dr Sanmi (Oluwasanmi) Koyejo, University of Illinois at Urbana-Champaign
- Sekou L. Remy, IBM Research – Africa
Nous tenons également à remercier les bailleurs de fonds qui ont soutenu cet appel à propositions, notamment la Fondation Rockefeller, Google.org, le Wellcome Trust, la Fondation Gordon et Betty Moore, la Fondation Patrick J McGovern et la Fondation Robert Wood Johnson.
Cet appel avait pour but d’aborder les inégalités dans les résultats en matière de soins de santé aux États-Unis et dans les pays à revenu intermédiaire de la tranche inférieure (PRITI) à l’échelle mondiale. Sur un total de plus de 60 candidatures, les équipes sélectionnées pour le financement répondront à toute une série de besoins dans le secteur des soins de santé, en faisant progresser les diagnostics médicaux, la lutte contre la malnutrition infantile, la gestion de la douleur chronique, et plus encore.
Les initiatives communautaires visant à développer et à exploiter localement des ensembles de données qui débrident le potentiel de l’IA pour apporter des solutions concrètes dans le monde entier ne cessent de nous inspirer. Sans plus tarder, nous vous invitons à découvrir la dernière série de projets sélectionnés pour un financement !
Équipes e Projet Financées dans le Domaine de la Santé
Microscopie sur Smartphone Assistée par l’IA pour la Détection Automatique des Parasites Responsables de la Diarrhée
Ce projet créera un ensemble de données d’images de systèmes de microscopie à faible coût basés sur des smartphones, afin de permettre la détection automatique en temps réel des protozoaires responsables de la diarrhée, même dans des endroits dépourvus d’experts ou de microscopes traditionnels coûteux. La diarrhée est la deuxième cause de mortalité chez les enfants de moins de cinq ans dans le monde, la majorité des décès survenant dans les PRITI. En utilisant des microscopes traditionnels et des microscopes basés sur des smartphones sur des échantillons de légumes, d’eau et de selles humaines provenant de provinces du Népal, l’équipe créera un nouvel ensemble de données annotées sur les kystes/oocystes de Cryptosporidium et de Giardia. Afin de fournir des résultats de référence, ils mettront également en œuvre et évalueront des méthodes sophistiquées d’apprentissage profond pour la détection automatique des kystes/oocystes de Giardia et de Cryptosporidium sur un ensemble de tests indépendants dont la publication est prévue dans le cadre de l’ensemble de données.
Nous nous réjouissons de lancer ce projet multidisciplinaire auquel participent des chercheurs et des professionnels de nombreux domaines différents, notamment des chercheurs en IA, des experts en microscopie et en optique, des experts en chimie et en dispositifs à faible coût, des cliniciens, des pathologistes, des experts en santé publique, etc. »
– Bishesh Khanal, Principle Investigator, NAAMII
Ensembles de Données pour un Diagnostic du Paludisme Basé sur l’IA
Ce projet vise à générer des ensembles de données de qualité, accessibles, étiquetées et en accès libre d’images de frottis sanguins et de gouttes épaisses provenant de l’Ouganda et du Ghana, qui contribueront à améliorer le diagnostic du paludisme par microscopie. L’équipe élaborera des protocoles de collecte de données normalisés pour l’acquisition de données d’image à l’aide de caméras de smartphones montées sur l’oculaire du microscope. Grâce à un partenariat avec les centres de santé locaux, ce projet permettra à la communauté de l’apprentissage machine de mettre au point des modèles basés sur l’IA pour la détection des parasites du paludisme, l’identification des espèces et la détermination de la parasitémie palustre.
Makerere AI Lab, en Ouganda, et MinoHealth AI Lab, au Ghana, s’associeront pour fournir des ensembles de données accessibles d’images de frottis sanguins et de gouttes épaisses en vue d’améliorer la microscopie du paludisme. En s’appuyant sur des ensembles de données libres et de source ouverte, il sera possible de créer des modèles d’apprentissage machine fiables et plus précis pour le diagnostic du paludisme, ce qui permettra d’atteindre l’objectif de développement durable (ODD) nº 3 : “Permettre à tous de vivre en bonne santé et promouvoir le bien-être de tous à tout âge”. Nous sommes très emballés par ce projet et infiniment reconnaissants au Meridian Institute de nous offrir cette occasion unique par le biais du Lacuna Fund. »
– Rose Nakasi, Makerere AI Lab, Ensembles de données pour la détection basée sur l’IA de l’équipe de projet chargée de la détection du paludisme

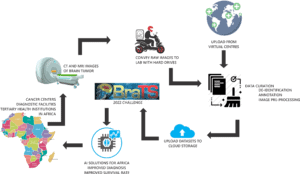
Élargissement de la Base de Données BraTS pour Couvrir les Populations Africaines (Africa-BraTS)
Ce projet permettra de créer une base de données annotée d’images IRM d’Afrique subsaharienne pour le diagnostic du gliome, une tumeur cérébrale rare, à croissance rapide et à létalité élevée. Au cours des dix dernières années, le défi Brain Tumor Segmentation (BraTS) a fourni des images IRM étiquetées de haute qualité, ouvertes et accessibles, pour la mise au point de modèles d’apprentissage machine pour la segmentation de tumeurs et l’évaluation des performances des modèles. Cependant, on ignore dans quelle mesure ces méthodes sont applicables dans les régions à faibles ressources, notamment en Afrique subsaharienne, où les taux de mortalité par gliome sont les plus élevés et où le recours systématique à une technologie IRM moins avancée, associé à un personnel qualifié insuffisant, rend le diagnostic des gliomes difficile. La base de données Africa-BraTS, élaborée à partir de données existantes sur les patients, constituera un moyen novateur d’évaluer les performances des modèles d’AM en vue de trouver des solutions aux défis de l’imagerie dans le monde réel et dans des contextes pauvres en ressources. À terme, cela influencera la manière dont les tumeurs cérébrales sont délimitées, mesurées et caractérisées, ainsi que la survie à long terme des patients.
Notre premier objectif est de résoudre les problèmes qui aggravent les disparités dans l’application de l’AM dans le diagnostic basé sur l’image dans les milieux à faibles ressources, en se concentrant sur les défis propres à l’Afrique subsaharienne. »
– Udunna Anazodo, Montreal Neurological Institute, Chair, Consortium for Advancement of MRI Education and Research in Africa (CAMERA)
Apprentissage Machine à Partir des Résultats Réels des Patients pour Réduire les Disparités Raciales en Matière de Douleur Chronique
Ce projet permettra de créer un nouvel ensemble de données d’imagerie conséquent fondé sur des résultats pertinents et réels pour les patients, y compris leurs scores de douleur, ce qui aidera à traiter la douleur sous-jacente pour les populations mal desservies. En apprenant à un algorithme à examiner les radiographies du genou et à prédire la douleur que les patients déclarent ressentir, plutôt que le score attribué par un médecin à la radiographie, l’équipe du projet a dégagé des connaissances médicales qui ont permis de mieux détecter les causes des douleurs du genou chez les patients noirs. Cependant, le défi que pose la généralisation de cette approche est que les ensembles de données existants sont insuffisants, car ils ne contiennent généralement que la radiographie du genou et l’avis du médecin. Grâce à cette nouvelle méthode, l’équipe utilisera les avantages uniques de l’IA pour contourner les biais inhérents aux anciennes méthodes de lecture des radiographies, et produire au contraire de nouvelles connaissances complémentaires à celles du médecin.
Ensemble de Données d’Imagerie Radiographique Thoracique pour Plusieurs Maladies Cardiorespiratoires
Les maladies cardiorespiratoires sont reconnues comme étant des problèmes de santé publique graves qui figurent toujours parmi les principales causes de décès dans le monde. Cependant, il n’existe pas beaucoup d’ensembles de données accessibles au public en Afrique, si bien qu’il est difficile de déterminer si les outils et les techniques mis au point dans d’autres régions géographiques sont aussi efficaces dans ce contexte. Cette équipe de projet créera un ensemble de données ouvertes et étiquetées de radiographies thoraciques pour plusieurs maladies cardiorespiratoires en Éthiopie, stimulant ainsi les chercheurs et les praticiens en Afrique, adaptant les méthodes actuelles au contexte africain et créant des technologies d’assistance qui renforceront les capacités de diagnostic des radiologues.
Cet ensemble de données devrait selon nous avoir un impact principalement dans la recherche et les applications du domaine de l’imagerie médicale. Il sera également essentiel pour les chercheurs en traitement du langage naturel et les entrepreneurs en imagerie médicale. »
Réduction de la Malnutrition Infantile au Chili Grâce à une Base de Données Intégrée et Multidimensionnelle
Ce projet créera une base de données intégrée sur l’état nutritionnel des enfants, les caractéristiques socio-économiques et démographiques, les résultats scolaires des élèves, ainsi que l’utilisation et les coûts des soins de santé liés à la malnutrition, au surpoids et à l’obésité chez les enfants au Chili. La malnutrition infantile est un processus pathologique aux causes pluridimensionnelles, qui accroît le risque de développer des maladies chroniques, augmente les dépenses de santé, réduit la productivité et entraîne une mortalité prématurée. Cette équipe soutiendra la création à la fois de l’ensemble de données et de l’infrastructure de base afin de les rendre accessibles en toute sécurité aux chercheurs et aux décideurs politiques tout en protégeant la vie privée.
La malnutrition au cours de la petite enfance peut provoquer des déficits permanents de croissance et de développement, et entraîner plusieurs complications de santé tout au long de la vie. Le Chili enregistre le quatrième taux d’obésité infantile le plus élevé des Amériques, et sa prévalence est plus forte dans les communautés vulnérables. En outre, la COVID-19 a perturbé l’accès à la nourriture et a eu un impact sur l’insécurité alimentaire. Avec le soutien du Lacuna Fund, une équipe interdisciplinaire de scientifiques et de chercheurs spécialisés dans les données intégrera différentes bases de données qui permettront de mener des recherches appliquées, afin d’aider les décideurs à se concentrer sur les populations particulièrement exposées, à créer des systèmes prédictifs qui contribuent à prévenir ces risques et à élaborer des interventions qui favorisent efficacement le changement de comportement. »
– Nieves Valdés, Principal Investigator, Équipe de projet chargée de la réduction de la malnutrition des enfants au Chili
Plateforme d’intelligence Artificielle pour la Numérisation des Documents Papier par Smartphone
Ce projet est axé sur le développement et l’utilisation d’une plateforme de vision par ordinateur et d’apprentissage profond de l’IA pour convertir les dossiers médicaux papier périopératoires en une base de données électronique. La consignation des données sur papier empêche la caractérisation, l’annotation, l’analyse et la conservation adéquates des enregistrements de données, ce qui diminue leur utilité pour réduire la morbidité et la mortalité périopératoires grâce à des interventions structurées d’amélioration de la qualité et à la recherche fondée sur les résultats. Grâce à ce projet, des photographies des dossiers médicaux papier d’anesthésie peropératoire seront prises par le prestataire de soins de santé à l’aide d’un smartphone au prix abordable. L’image sera déconstruite par segments et numérisée à l’aide de modèles de vision par ordinateur, créant ainsi un ensemble de données étiquetées. Les ensembles de données numériques périopératoires permettront ensuite aux prestataires de soins de santé de mettre au point des modèles pour identifier les prédicteurs à haut risque de complications postopératoires qui sont pertinents et spécifiques aux PRITI.

Vers une Base de Données de Radiographies Thoraciques Liées à la Tuberculose Adaptée à l’apprentissage Machine pour l’Afrique
Ce projet vise à créer un ensemble de données ouvertes et étiquetées pour les radiographies pulmonaires et les informations cliniques recueillies auprès de la population ougandaise, afin de faciliter le dépistage, la détection et le diagnostic de la tuberculose. Dans un premier temps, l’équipe mettra au point une formation certifiée pour les radiologues et les professionnels de la santé sur la reconnaissance des schémas de radiographie thoracique. Le personnel formé effectuera ensuite des radiographies pulmonaires sur des cas suspects et diagnostiqués de tuberculose dans des centres de santé sélectionnés et sur leurs contacts pour lesquels une radiographie est prescrite. Il produira des rapports factuels à partir de sa propre interprétation, téléchargera les données et les rapports et travaillera avec des radiologues experts pour obtenir un second avis. Les cas suspects dont le rapport de dépistage par radiographie pulmonaire est positif devront subir un test de confirmation, et pour les cas diagnostiqués, les données seront extraites des rapports des patients. Les rapports de dépistage et les tests de confirmation seront utilisés pour générer des étiquettes pour les clichés de radiographie pulmonaire. Sur la base de tous ces éléments, l’équipe créera un ensemble de données étiqueté et inclusif comprenant au moins 2 000 radiographies pulmonaires uniques et des données cliniques.
